Making Asynchronous Release Schedules Easy On Your Development Process
Once upon a nightmare a project manager said to me: “I would never let developers work on trunk.”
Serious? It turned out the organization had *redefined* from industry standards the definition of “trunk” — to them it meant “production release.” Ummmm. Ok.
I explained why the concept of trunk is that it is the most advanced rendition of the code, that development is always ahead of production and that production is just a release of developer code. No matter how you look at it this is the truth, even if you do hot fixes or patches in production (which should be patched back to development or forgotten with production that becomes a dead end branch.)
The repository is there to support development. Part of development is release. If the philosophy is the converse: repositories are there for production release and developers-be-damned I can guarantee you rough seas.
Two scenarios I have worked with that deal with extreme repository interesting situations:
- Divergent Branch Problem: A branch that diverged with trunk so far that it went on its own release schedule and eventually became its own product. You see this kind of branching in Github all the time. If this happens, and an organization is still under the delusion that they have one product its too bad — but the behavior of the team will be supporting two products. Solution: drop your delusion. You have two products.
- Asynchronous Features Problem: In this case the teams have several features coming out but no one knows which will be released first. Solution: Make branches and merge back to trunk often. Have build servers on all branches . . . and read on.
The Asynchronous Cake Batter
We had two competing Features, A and B. The features were to be released separately, the first one exclusive of the second feature’s code but no one knew which would be the first to be released. Got it? Parallel timeline. AND. . . they had all the developers on all features checking into the same common trunk. Oh yes they did. Eventually the “build master” would do a reverse merge in trunk when a build was needed. using check-in tags to could identify what to pull out, and create a release from what was left. That’s right — a reverse merge.
Pause.
A “reverse merge” is pulling code out to create a build with the intention of putting the code back again.
OK, now that you’ve wiped the Dr. Pepper off your screen from your guffaw, and believe my I couldn’t believe it either, nothing would budge them. They wouldn’t create dedicate branches — indeed, even using SVN they could have, and none of the teams were really sure what a build number meant out in QA. You’d get build 456 and say “hey. . are you testing Feature A or B”? Only the build master knew from the edict he received from management. Yeah, our QA systems were testing both at the same time on the same systems. And services were going out too — so sometimes a Feature A client would be operating on a Feature B service.
And the worst part was the releases suffered from cake batter syndrome — that is, once you’ve put the eggs and sugar into the batter and its baked you can’t get them out again. Reverse-merging suffered from this: the resultant code was nothing nobody had created. And . . .the build masters didn’t work on the code at all but they had to do this complex merging.
My Solution
I was able to manage things my self locally with git and git-svn for our respective repositories. After hands-on with this I came up with the solution in the following diagram.
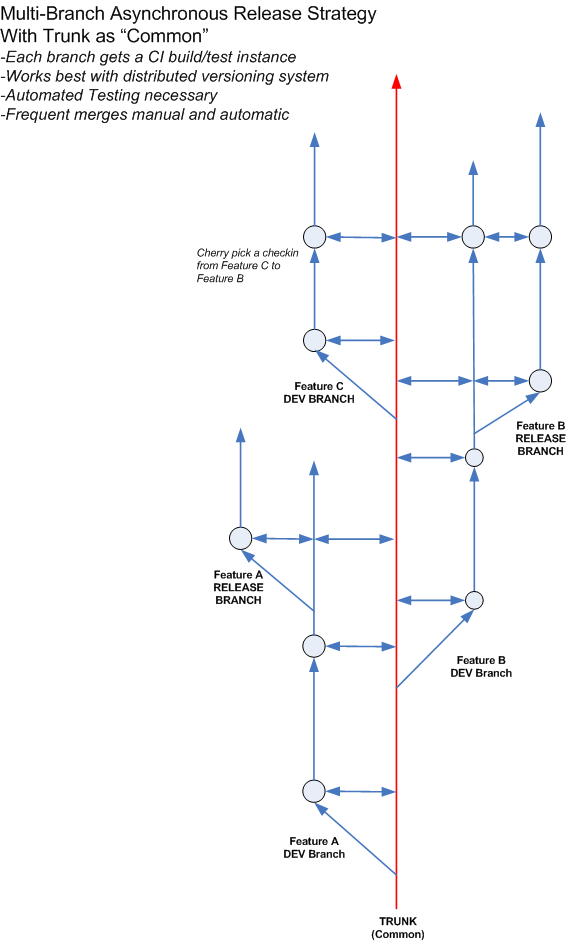
The features are branches where the developers work. The pain comes in merging back to trunk, but doing so ensures that a future branch gets all the previous features.
Discussing this solution with a few outside that particular culture, this makes sense. Hg or Git really go a long way to help this. A developer can switch easily between them.
Also — very important — is the merge back to trunk from the branches. Now who does this is up for contention. A merge requires builds and tests and can be time consuming. My suggestion — automate the merge back to trunk on developer check-ins and run the builds with automated testing. A breakage means a peal off.
I really think you need three ingredients to do this kind of development — or be ready to descend into the hell we experienced:
- A distributed repository that makes branch creating and switching a snap — like Git or Hg.
- A build server with a crew ready to clone build jobs for the necessary branches (minimally the mainline trunk and feature branches).
- Automated testing — to ensure that nothing breaks.
- Frequent and often merges
I cannot suggest this kind of management paradigm that creates this scenario — even with the solution I put forth there is considerable pain in the merges no matter what a person can do. Double check-ins have to occur somewhere when an organization decides to do this, but its better than the dratted reverse-merge.
git, hg, repository, vsn