Localstorage is a newer way to store data locally in a browser, kind of like a cookie. It is supposed to have a much easier interface than cookies and can do JSON. Another developer I know was using this and she was using localstorage to track local data for some dynamic web interactions. Nothing will get sent back to the server — you’d still have to use cookies for that (example – a JSESSIONID). But considering that much of the javascript I’ve written in my life was managing browser data by doing “single page websites” or passing form data with hidden fields back and forth, or passing data via query parameters — the localstorage idea is very compelling.
I did a little searching and this succinct post on HTML Dog has a nice example.
My interest for this post is in the tooling around localstorage.
What I want to do is create a localstorage entry and then see it in a tool like Firebug or a web development tool much like a cookie. I’ve chosen Firefox built in web developer tools for now.
First, I have to create some localstorage. I navigate to this blog site and open up Firefox’s developer and toggle the toolbar
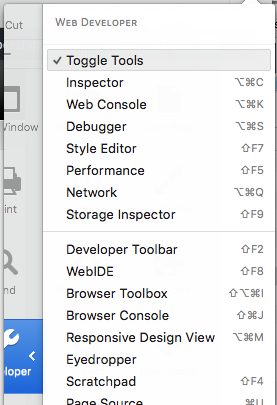
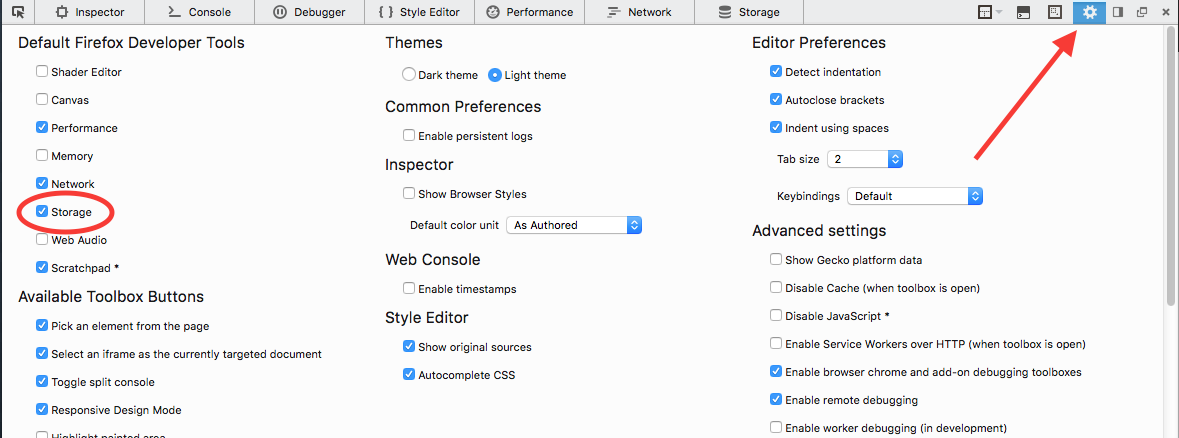
Click on the Toolbox Options and then check Storage.
Create a localstorage value, I’ll just use HTML Dog’s JSON Example, and include a println to show I can try out the setter/getter functionality.
localStorage.setItem('user', JSON.stringify({
username: 'htmldog',
api_key: 'abc123xyz789'
}));
var user = JSON.parse(localStorage.getItem('user'));
print(JSON.stringify(user));
Execute it in the console of the developer’s tool.
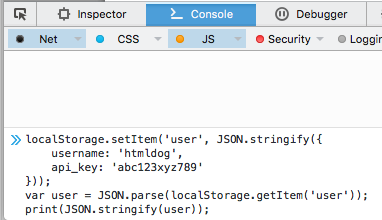 And after.
And after.
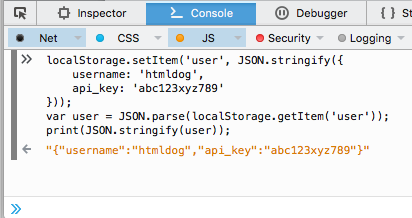 We received the data back correctly for “user” object . . .
We received the data back correctly for “user” object . . .
“{“username”:”htmldog”,”api_key”:”abc123xyz789″}”
Look in Storage. Wow! that’s a lot of cookies.
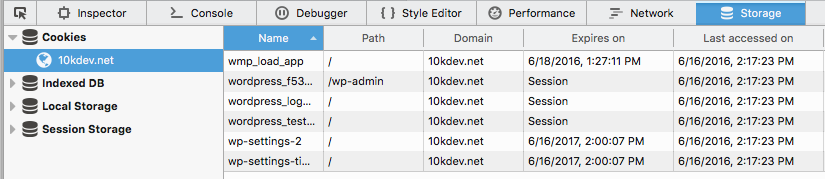
And here is the localstorage data for “user”:
 You probably see the other two storage entries:
You probably see the other two storage entries:
- IndexedDB is a low-level API for client-side storage of significant amounts of structured data, including files/blobs.
- Session Storage – The
sessionStorageproperty allows you to access a sessionStorageobject. sessionStorage is similar toWindow.localStorage, the only difference is while data stored in localStorage has no expiration set, data stored in sessionStorage gets cleared when the page session ends.
Persistence differences! Well that’s really good to know about local vs session. Browser support as of this date: