I haven’t been at this in a while although I have a backlog of things to write about that I have been accumulating from my readings and talks with other devs associates over the last few years. Unfortunately some of it is timely technical material and the relevancy has probably fallen by the wayside.
One thing I have been wanting to start up again were my hands on tech groups and have been looking for some focus since there are so many things going on right now. Since deciding not to use the Meetup site for EC Tech, I’ve been trying to come up with something that was a little more deep than just a glossover 101, because, that’s what the world needs is more glossover 101’s on tech.
So, right now in the boil are these topics:
- Security topics — oauths and verifications etc. I have gotten some experience since the lat 20-zero’s in this sphere and have always wanted to finish out the investigations.
- Mobile application platform evals — are languages like Kotlin worth it vs Java etc., and quick launch but flexible-to-adapt platforms. Are mobile apps even worth it even.
- General language/platform investigations with business ideas — I am looking at Y Combinator courses this summer and their materials — people can sign up.
- IoT. There are a lot of robotics and such in my area; a deep look at machine programming might be worth it. I see a lot of the raspberry pi work etc. but not interested as much as capitalizing on the real world. Note I am very much in favor of dumb machines, well, what about IoT for them? And ownership over the code you purchased with that machine?
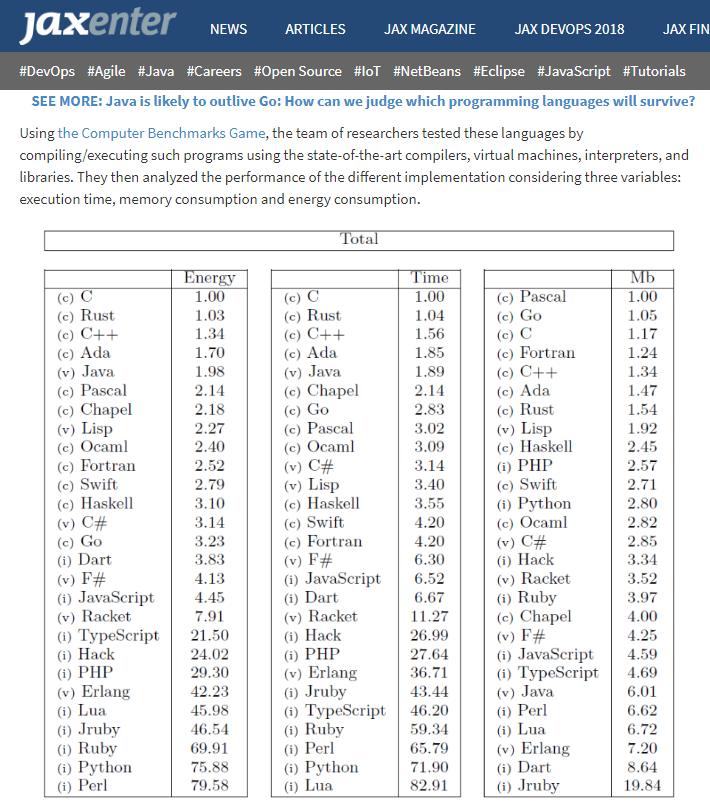
- Big data beyond the incessant people tracking psychosis a lot of the industry now practices.
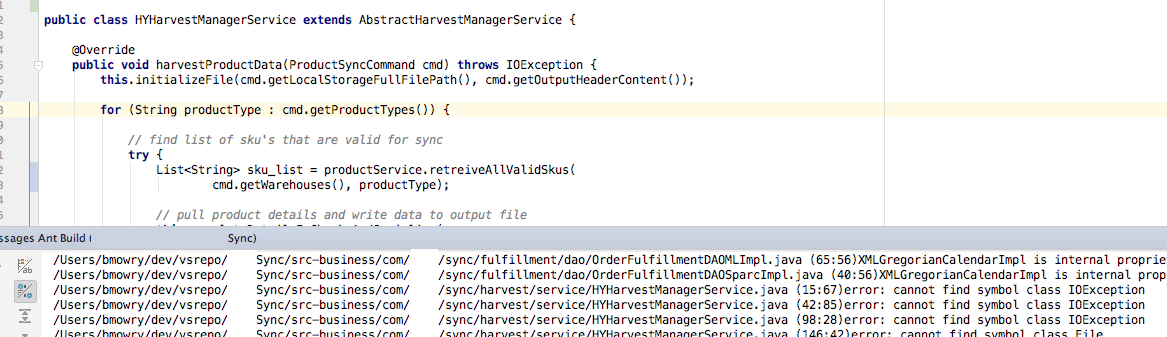
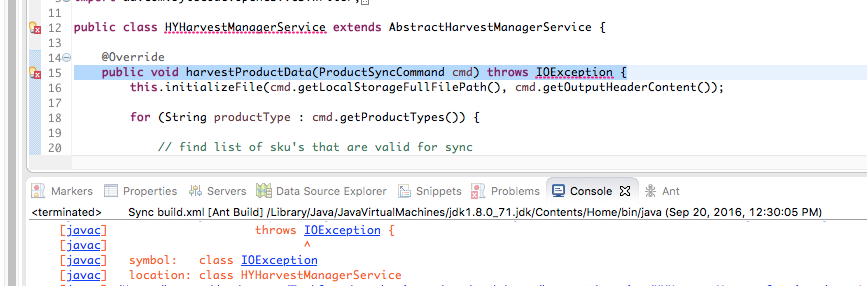
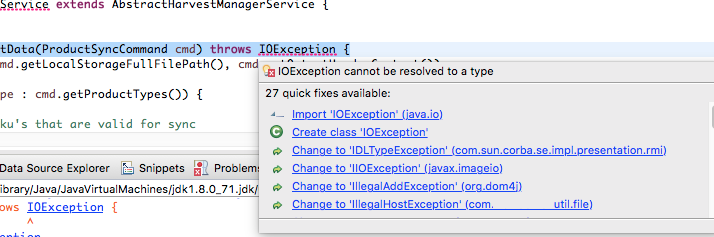
The tech world is going back through a cycle of microservices (“write once, run everywhere” like 1990’s java) and ideas that were being used by developers but surfacing just recently — like cicd — seem to me to be as buzzwords or adapting tools we already do so, anything I do will encapsulate some sort of those aspects. Mostly it is the materials that dictate it — tech — and not a grandiose vision of things yet to have been.
Of course I have some agile/lean/etc. topics to write about. I usually keep these close to the vest as the outcome of those techniques end up on a developer’s lap, much like physicists never see atoms in an accelerator, just the aftermath.
Also, I am looking for a good platform to share with everyone, all this. Since my group was localized, maybe it’s time not to do that? Do not know. Having kicked around podcast ideas since 2007, and doing online/youtube things it just didn’t catch my interest, and, there is a lot of good stuff out there now.
The trick will be — doing something relevant (to me and/or us), and hopefully capitalizing. See you soon.



 I was reading through some Code Newbie tweets and was quite impressed with the enthusiasm of potential developers who had little, if any, work experience. Well I’ve got some news for them. Know that stress you are having at finding your first job, doing your first job, doing any job?
I was reading through some Code Newbie tweets and was quite impressed with the enthusiasm of potential developers who had little, if any, work experience. Well I’ve got some news for them. Know that stress you are having at finding your first job, doing your first job, doing any job?