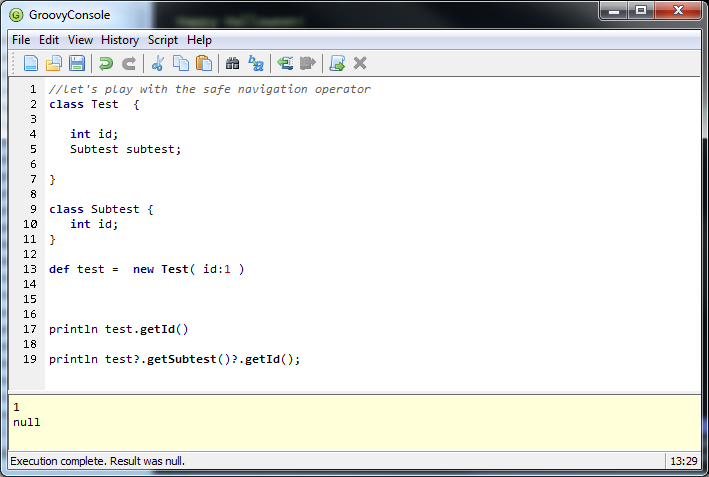
“Package versions? As many as there are stars in the sky.” – Dances with Dependencies
I’m sure many developers have been finding nodejs buried in pretty much everything these days, and that can mean dependency management with npm and package.json. And more often than not I am finding version collisions and dependency needs unmet in non-trivial and time draining situations.
Working on a large commerce engine, it fell to my shoulders to do a minor version upgrade.
Versioning on some pieces have been very discrete: JDK7 (for now), Ruby 2.2.2; jstl 1.2 libraries and specific jdbc drivers. The vendor ignored specifying versions and “get the latest greatest” rules the roost for ruby gem packages and nodejs. So far the who-cares-what-version gems have not been a problem (but they *will* be, can almost guarantee it). Other packages needed for node aren’t specified in package.json, allowing for the pull of the latest-greatest as well.
I have a few setup tasks, then to run npm install in the project to pull the node modules, then do gradle build. We can run it from there.
First the vanilla try: I run npm install, then gradle build — breakage on the build:
Running “sass:dev” (sass) task >> (base: #CE1A2B, light: #e63546, dark: #a11422) isn’t a valid CSS value.
Working with two other team members, I got a hint: we needed to specify a version, decided by magic (trial and error) in package.json, a dependency entry:
"node-sass":"3.2.0"
That fixed some problems with our EXISTING builds; this breakage was intermittent and now in hindsight I am guessing due to a race condition of node-sass dependency pulls; get lucky and the right version wins. We propagate the fix to the repository.
But for the minor version upgrade I was working on? Didn’t work. Running npm install would generate an error:
Cannot download “https://github.com/sass/node-sass/releases/download/v3.2.0/win32-x64-46_binding.node”
Digging through github to see their releases, well, there is no minor version of -46 for node-sass 3.2.0. The newest version being 3.4.1 right now — but that version (pulling latest-greatest method, our initial methodology problem) which has a -46 breaks the build due to the css error mentioned above. Another very strange thing is that no matter what version I put in, it asks for the -46 rendition; as if when I specify a version in package.json it only parses teh x.x.x part, but doesn’t allow for me to specify the -xx version part.
Running npm install –dev was a huge mistake as it pulled the universe down and still broke; when I went to delete the node_modules directory there were really long file paths that Windows hates to delete. I had to rename tons of recursive folders to “a”. Cost me at least an hour to bail out of that route.
So I started to climb through the repository for node-sass up from 3.2.0, and found a 46 release for version 3.3.3. I tried that, and it worked and built. I don’t know why, I can’t generate a legible dependency tree or run a dry run with npm-install.
It’s disconcerting though — why 3.3.3 other than it has a -46 rendition? There’s no vendor explanation. And only a long regression test will say if it really works. I talked with the local nodejs expert and asked questions about the type of dry-run I’d like to do with npm (from what I understand, and how to get a dependency graph and figure out what version I need — this is the next step to line up with the regression tests.
Specifying package versions seem to have a shortcoming, in my opinion, as well. This article from nodejitsu does a great job at discussing semantic package naming, but there doesn’t seem to be a way to specify my -46 release and the article kind of confirms that (I tried every syntax under the sun). Here is the syntax for package.json, my situation concerned with dependencies, and I tried different things without success. For instance specifying “~3.2.1” which is an approximate-equivalent provided a successful npm install, but not a successful gradle build.
The npm system isn’t quite as mature as say maven but it is making leaps because people like you and I are coming in with experience on different systems and use cases to contribute. For now though, I have to dig down into the dependency graphs even further, and better yet, ask the vendor to list versions of packages it needs for its software instead of assuming the latest-greatest will always work.