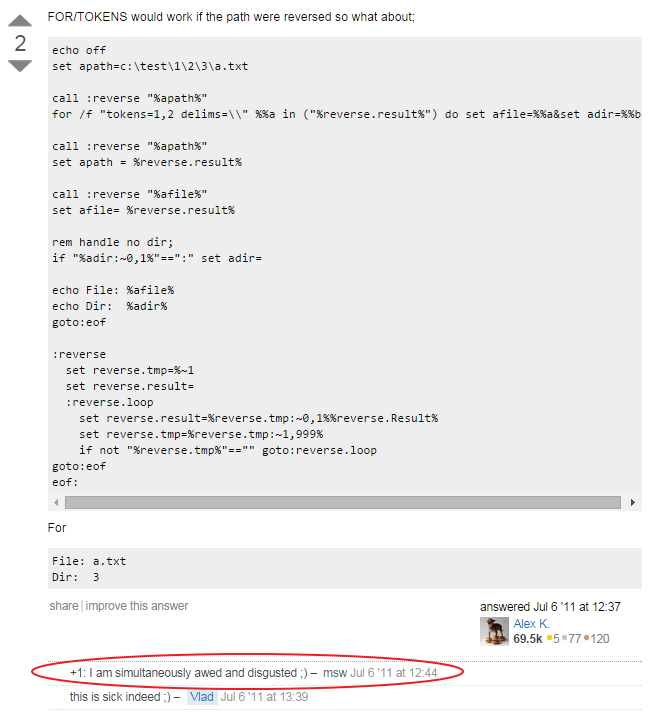
If you want to start up your grails server in a different timezone (for instance to test your client as if it were not co-located in the same zone as the server) just add this to BootStrap.groovy:
TimeZone.setDefault(TimeZone.getTimeZone("PST"))If you want to start up your grails server in a different timezone (for instance to test your client as if it were not co-located in the same zone as the server) just add this to BootStrap.groovy:
TimeZone.setDefault(TimeZone.getTimeZone("PST"))
Delicious snake oil. LEAN and healthy.
I think finally the outrage against the manipulation of Agile methodology is coming to full head.
Years ago in discussions with colleagues we came to the conclusion that Agile had a built in flaw: it allows people to manipulate the software management process for their own goals, and since everyone does not have the same goals, this creates conflict and in the end a bad product.
You can take note from this article by Erik Meijer: AGILE must be destroyed, once and for all. This kind of angst is showing up everywhere: let us just develop software, dammit, and stop micromanaging us.
Now certainly I understand that management needs a way to measure it’s field hands to assess productivity. I get it. I understand there have to be measures in place to assess risk and holes in software’s security, code stability, defect management and the like. Agile has created a systemic problem whereby all this get’s bypassed. How?
There are things that I like about the industry. I like a lot of the testing, as long as it is used sanely. I like the continuous integration engines. I like some of the documentation things about projects in the new tools. But I am not sure we are writing software any better or faster than a decade or two before.
One thing that burns me is the lack of objectivity in the industry and the winning by the “verbal” people to use religious and orthodox arguments to get to their goals. This is . . . political. Which means objectivity is out the door. A great Ted Talk video explains how this happens in what is the holy grail of objectivity, the scientific method:
If objectivity has been removed from the process because the goal, good software, is put on the back burner so that political achievement can be obtained, well then, this is a weak methodology. And software developers are no where near as objective as scientists try to be. This kind of fundamental flaw pervades the processes of management, development, and testing.
Finally, so you sit down and make all these complaints. And still, still, the biggest gap in all of this is that requirements gathering is *still* the number one complaint of all projects I am on. Developers invented CI and analytic tools to make things better, but we haven’t seen a breakthrough in design and requirements gathering.
And that is interesting. If Agile isn’t accommodating the processes of innovation, design, and requirements gathering then it isn’t accommodating its simply stated goals:
Personally, I’ve never bought into that utopic mantra. I guess the manifestation of it’s failure is at hand. Though, at least it was tried and allow to fail and we have gathered a lot of great learning and experience from trying.
Just a note that the kickoff greeting meeting for the new Western Wisconsin Groovy Grails Group went without a hitch.
I will probably expand this out into a separate Meetup, to separate it from the EC Tech meetup which is hands on focused. It’s been difficult recently to find time to do this with massive family happenings, but will just keep the course.
See you all at the next meeting!
I just did an install of IntelliJ 14 on my development Mac running OSX 10.9 (Mavericks).
When I started the IDE it erred “you need to install Java SE 6.”
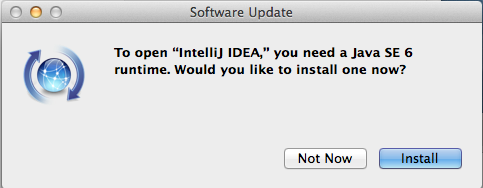
That was hard to believe. I had 7 installed. IntelliJ is reporting the version it needs to run itself, even though the applications you are developing wouldn’t have to be 6. Personally I thought this nuts as most places are sunsetting Java 6.
The solution is go to Applications->IntelliJ IDEA 14.app->show package contents. Edit Info.plist and change “1.6” to “1.7”:
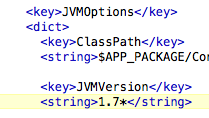
Now it runs on 7.
So, you have a directory with a java class in it, and you want to use your IDE on it. What do you do? You can’t just open it up as a project without a little bit of work. IntelliJ can do it from the GUI, but with Eclipse and Maven you have to do a bit more work. Also, if this directory is already checked in you’ll want to preserve
Add a simple pom:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.menards.casetest</groupId>
<artifactId>CaseTest</artifactId>
<version>0.0.1-SNAPSHOT</version>
</project>
Then add a project folder structure like this:
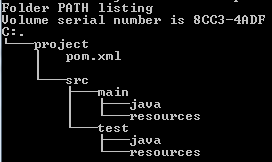
Now you have something you can import as a Maven project into many IDE’s. If you are already checked into Git before this, then just move your source files under main/java/whatever path and check that move in.

“It’s a Madhouse” for $200, Chuck.
This is a strange one . . .
Most of our development for a services project is done on Windows. Java, Spring, Hibernate, Drools, JAX-WS. I was integrating some more service calls and refactored the names of a few classes from (something like):
CALLService.java
CALLServiceImpl.java
to
CallService.java
CallServiceImpl.java
Sounds pretty simple, right? Checked it into Git running ff a Stash server, and everything was building fine. We did not however have a Hudson build running off this particular branch to check it for sure, but still, we were all good.
Along comes a developer working on Linux. He checks out the code and BAM it breaks. Spring is complaining, need unique service names. Now way! I check out the code on my own Linux instance, and the build fails. Looking in the code I see this in the Linux version of the project’s services directory AND I see this out in Stash:
CALLService.java
CALLServiceImpl.java
CallService.java
CallServiceImpl.java
No kidding! Going back to my Windows machine I do a fresh clone, and look in that same directory. What do you think I see?
CallService.java
CallServiceImpl.java
LOL! No sign of the upper case classes! It builds too.
My solution — I go back to Linux, delete the CALL files, check that in. Now Linux builds fine, but guess what? Back on Windows, I do a few “git gc” cleanup calls and it keeps wanting to delete the Call files I want to keep; gosh. Do I need to re-add, again? Ugh. Instead I do another git pull –rebase, and on Windows, finally, it’s all good, on Linux it’s all good, and Stash is all good.
Side note: I also got the old “LF will be replaced by CRLF when operating on some files.” errors from git on some operations. I noticed quite a few files were being checked in as ISO-8559 from the Linux developers, and I set myself up as UTF-8 on Windows to mesh with them in the first place! It’s a madhouse! Won’t get into it today, but it made for some interesting editor experiences.
Theories?
I tried spiking this out through a GitBlit I had running on my Linux machine. I made a project, checked it out, did some case-sensitivity-changes in Windows. But I never saw this error on the Linux machine after checking them in. I stopped there, and don’t want to mess with Stash anymore. I remember Gitblit has problems with cache cleaning and showing multiple project views of the same project, but this was different.
Windows is notirious for being not-case-sensitive, and Linux is. I am guessing, somewhere, I made the case changes and checked them in but a disconnect happend with the Stash server that saw the changes as new files. On SVN a rename = add + delete. That makes it problematic when the sysadmins are messing with permissions and preventing deletes. Maybe our sysadmins stopped my delte permissions for a day. Then during this operation the add was executed, but not the drop — and a Linux Stash server certainly could have seen the case changes as new files.
During checkout, Windows sees the files as the same. And some hocus pocus writes over the old names. But Linux was never fooled for a second.
I don’t know. I found the problem, I fixed it. In the industry sometimes I can’t spend three days figuring out something. I note it, throw it in the team wiki, make a blog post and move on.
 I was hesitant about doing the Hoodie work session because plastered all over its site are statements like the above. But I decided to go forward with it — it was only 1.5 hours to start. That 1.5 hours turned into about 4 hours total.
I was hesitant about doing the Hoodie work session because plastered all over its site are statements like the above. But I decided to go forward with it — it was only 1.5 hours to start. That 1.5 hours turned into about 4 hours total.
None of this is simple. That’s what Hoodie reminded me. I spend a lot of my developer time patching together libraries and probably incompatible technologies — it’s one of the existences of developing. Most systems, it’s very difficult to show up onsite and just start coding.
No Backend?
Hoodie is a web app stack that *claims* to be “no backend” — where there is no need for any backend developers. Having been a developer for over 20 years, and reading the noBackend.org site mantra –“front end developers making a full stack.” Well . . a full stack also encompasses the back end. I think what they are getting at is a more automated back end. But you still need data storage, you still need clockworks for SFTP widgets, you still need batch engines and jobs, you still need email engines and api’s for your service buses. Hoodie uses CouchDB . . . that’s not exactly front end. So honestly, I am throwing out this idea of “no backend.” There can be less backend, and maybe a world with no coding altogether? Some of the people on Hoodie’s site claim not to be coders but can make applications. Sigh.
The Backend Installation
Installation of Hoodie turned out to be a pain-in-the-astroturf on all platforms. Windows 7, OS X and Fedora 20. I blew all my my EC Tech time trying to get CouchDB running on Windows. That’s very backend. When I finally got it running in a VirtualBox image of Fedora20 — I had to wait almost an hour on a very fast network for Hoodie to install on top of it’s prerequisites — Git, CouchDB, and NodeJS, and NPM. And once you issue “npm install -g hoodie-cli” on Fedora, you wait for a long time while it pulls down every imaginable JavaScript library in the universe.

Science! Er, I mean, what is the *real* meaning of Hoodie?
During this package install I think I saw go by . . . backbone, angular, marionette, handlebar and underscore for starters. If you want to know you can dig out in their git hub at
https://github.com/hoodiehq/hoodie-cli.
Which brings me to a curious question.
In this paradigm, isn’t Hoodie technically the “backend” developers using JavaScript tools for “front-end” developers who use their api’s?
Mindblowing.
The Experience
Here is a list of some of the interesting experiences I had during installation:
Fedora 19 has been out since July 2, 2013 and still isn’t supported by VirtualBox?
Humorously, the topic of choosing public networks wisely has come up often in the last few weeks among my colleagues. CHOOSE YOUR SITE WISELY! Oh and that 4G tethering — OK for texts sites, but it’s still slow. One time I went into a Starbucks with a new project I downloaded and a single issuance of mvn clean install -U cost me an extra coffee. Download times in many public networks suck, so choose wisely you meeting site or come prepared.
Choose your public networks wisely, young Skywalker.
My general feeling was, though, that CouchDB had a tendency to need security dinking and the Hoodie downloads themselves took forever. I finally got the application up and going and, well, was not impressed. It would need a LOT of coding. The promise of out-of-the-box and no backend developers needed is, in my opinion, not quite addressed by this platform. I’ll revisit it in a few months.
Last Thoughts
As far as Hoodie goes, even in its cursory stages, the mission and the technology probably will never meet my needs. Later on in EC Tech we are looking at the viable MEAN stack and I can code Grails, I have almost no need for Hoodie. Looking at what they’ve done, I am not sure what kind of business it could address but there didn’t seem to be an easy place to drop in rule-based coding and specific, specialized domains. This is a huge problem.
Hoodie is full of stuff. If you want to use it, you will have to become good at CouchDB, NodeJS and whatever JavaScript libraries they are using. Keep this in mind. You are just getting their “paste” — as if (in Java) someone did all the Spring configs and you would have to live with them. In my experience this creates more meta-problems to deal with, rather than code. The cusom route might be the best way to go for your UI in this case.
Is it enterprise? What about using a domain/data expert for design? My feeling is . . .scalability issues, swapping databses etc. — all that would be a problem. Maybe in the future they will change that.
For the hands on sessions of Eau Claire Tech Meetup, I will do some prep work and create a VirtualBox setup I can give to someone if they need it. These are usually too large though to continually host somewhere, and not worth making public right now. I *could* make a Vagrant recipe available but that involves having Vagrant, Chef, and VirtualBox installed prior to coming in for the hands on. That’s a lot of prep, to do more prep , to get the prep out of the way.
Finally, being a developer IS doing configuration work. The point of the EC Tech hands-on’s is to take the time out to do that and be around others, like a practice. A lot of my professional work is struggle with problemsome frameworks, poor documentation, and square peg-round hole solutions. That’s what it is. Time spent debugging any problem is well worth it; especially since I have not yet seen a out of the box framework do exactly what it says it would and we would ditch it for bare bones.
I’ve been slogging my way through some testing frameworks for EJB: The Grinder, Cactus and JMeter — trying to find that quick Soap UI style entry into testing EJB. No such luck. This will take some work.
So, I decided to remind myself just why we ere doing EJB in this application. I bolded the main points. Maybe we can make an acronym . . . .
A simple explanation from DevGuru:
Some of the things that EJBs enable you to do that servlets/JSPs do not are:
A very thorough answer from Stack Overflow:
@Stateless
public class MyAccountsBean {
@EJB SomeOtherBeanClass someOtherBean;
@Resource UserTransaction jtaTx;
@PersistenceContext(unitName="AccountsPU") EntityManager em;
@Resource QueueConnectionFactory accountsJMSfactory;
@Resource Queue accountPaymentDestinationQueue;
public List<Account> processAccounts(DepartmentId id) {
// Use all of above instance variables with no additional setup.
// They automatically partake in a (server coordinated) JTA transaction
}
}A Servlet can call this bean locally, by simply declaring an instance variable:
@EJB MyAccountsBean accountsBean; and then just calling its’ methods as desired.
OK not so sure about “simplicity.”

I’m Comin’, Maw! I’ll save yer application!
When I start to look at the cost of leaving quality to the wayside I’m reminded of an experience I had with a coder, Big Hero.
Now back when I was a *high school athlete* in American football our coach coined a term: dummy hero. Football has a practice fixture called a scout team — the group that practices against the starters to help the starters get ready for a game. A dummy hero is on the scout team, and pretends they do not know the play that is being practiced, but as everyone they actually do; everyone does because its repetitious practice. But instead of playing it straight, the dummy hero would make a heroic effort and come up with an interception or run a touchdown even though the point of the exercise was to have the starters practice. They interfered with practice to make themselves look good.
Big Hero types are dummy heroes. In their case they break things and fix them in the nick of time. They could pay attention to quality, but do not; writing off deliberate, methodology for the thrill of late night release parties. And chances to be a hero.
The content you are trying to access is only available to members. Sorry.
The one pass XSLT, it is the least.
A two pass XSLT, now that is a beast.
But I would give a silk pajama
To never do this three pass drama.
We have data that comes in from a SOAP server that is in pretty bad shape. I have a feeling the team that makes this is using a direct Oracle utility to pump it out of the database so as not to have to do any cleaning up or development. Most of the non-alpha/numeric characters are replaced by codes, like this:
<BATCH xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance” batchid=”EnterpriseTransaction” version=”2.0″ xsi:noNamespaceSchemaLocation=”config/xsd/DataReplication/2.0/DataReplication.xsd”>
<TABLE_METADATA>
<TABLE name=”TR_TRN”>
<COLUMNS>
<COLUMN name=” …
YUCK!
One of the teams wrote a two xsl sheets to tranform this nasty xml data — and is used during our web client’s consuming of this data. But sometimes we want to transform it outside of the program to use it for integration tests or just look at the data for errors. Most of the developers use the transform tool built into Eclipse, and I have been using a java gui called jSimpleX. But this being a TWO PASS xslt process, its a pain in the ass. And, the last output is unformatted into a single line, all the carriage returns stripped out. So I have to go to an online tool like FreeFormatter to finish the task — making this a THREE PASS transformation.
I decided to automate this a bit. I looked for some command line tools to batch something out.
First I ran across the old tried and true Windows msxsl.exe. It worked ok on the first pass — but unbelievably, crazily, choked on UTF-8 data. A serious WTF moment.
The good old xalan. I stopped this very quickly — trying to integrate it into a “simple” java or groovy script. Operative word being simple. And not having a lot of time from the pm’s to do this, and running into xalan’s poor documentation and need for tons of dependencies I dumped it.
Wow is this really that hard?
So I tried Groovy — I have a lot of experience with the slurper objects. But . . .. . of course my data exceeded the 65536 string max length.
Then there was Ant and it worked OK. Just OK —
Finally, I tried a tool called xmlstarlet. Bingo. Would do transforms AND formatting.
Why are the tools to handle XML so lacking these days — when lots of Big Data tools like MarkLogic and BaseX use XML; and SOAP isn’t dead because of it’s capability to do ACID transactions?
My batch file calls with xmlstarlet look like this:
xml tr phase1.xsl %TEMPFILE%.xml > %TEMPFILE%_phase1.xml
xml tr phase2.xsl %TEMPFILE%_phase1.xml > %TEMPFILE%_phase2.xml
xml fo %TEMPFILE%_phase2.xml > %TEMPFILE%_formatted.xml
So here I have the two transforms, with a format at the end. Super slick.
I had to write a little command interface for file input after that. Needed a refresher — so went looking. And ran into a Stack Overflow page that pretty much sums up my feelings on doing this part of the task. Awed and disgusted.